These tasks were created as part of the Information Retrieval course at the Ben-Gurion University of the Negev.

The course deals with a variety of subjects on Information Retrieval and its application on the Internet, digital libraries, and information science. It covers the following topics:
-
Classical topics: information retrieval models, information retrieval algorithms, indexing, data structures for information retrieval, and evaluation of information retrieval systems.
-
Advanced topics: ranking methods, multimedia retrieval, thesaurus usage and creation, data mining, and harvesting.
-
Information retrieval on the internet topics: digital libraries, basic and advanced search engines, electronic newspaper, and distance learning.
The goal of this project is to apply the theoretical knowledge learned in the course and acquire practical knowledge of the development and evaluation of search engines. The project is implemented in Java using the Intellij environment. The project includes two programming phases – indexing and retrieving.
Indexing the Documents (First Phase)
In this part we implement the processing and indexing of the documents. The corpus of documents includes approximately 450,000 documents, divided into around 1000 files. Files have fixed structure with XML style tags such as <DOC>, <DOCNO>, <TEXT>, etc.
Several project’s main classes of this part:
-
ReadFile class – Receives a path to the folder of the corpus, reads the files in it, and separates the documents.
-
Parser class – Separates every document to terms according to specific parsing rules regarding general words, numbers, dates and timestamps, entities, etc. All the entities that appear in more than one document are stored in a different index, dedicated to entities.
-
Stemmer class – Stemming is the process of reducing inflected (or sometimes derived) words to their word stem, base, or root form. This class is implemented using an open-source stemmer (Porter Stemmer).
-
Indexer class – Receives all the terms from the parser and creates an inverted index. The inverted index includes a dictionary of the terms and temporary posting files. To have the optimal time and space complexity, the writing to the disc occurs in batches of documents, instead of one by one.

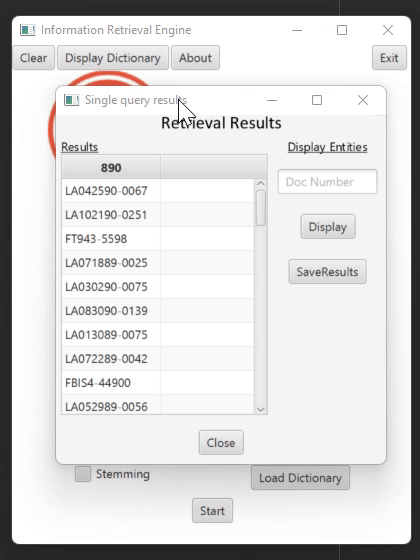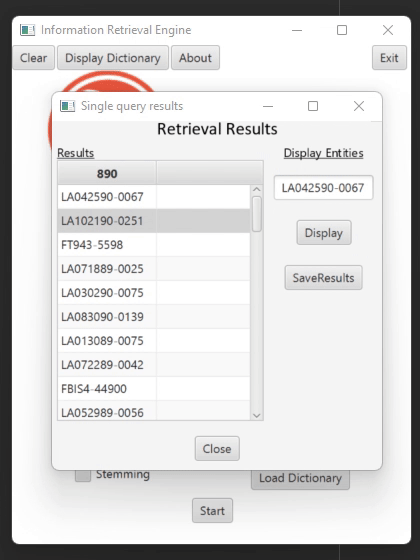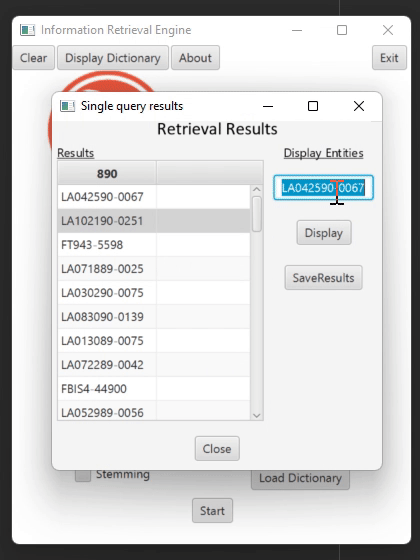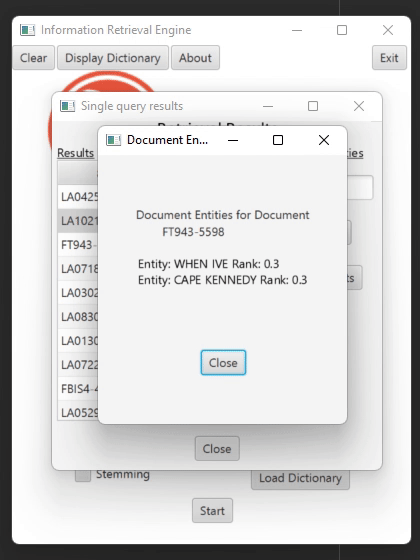
Retrieving Relevant Documents (Second phase)
In this part, we implement the search and retrieve framework. The search engine receives either a single query or a path to a file that contains multiple queries, and then it retrieves the most relevant documents that match the query.
Several project’s main classes of this part:
-
Searcher Class – Receives one or several queries and searches the documents in which the terms of the query appear. The united list of documents for the query is then passed to the Ranker class for sorting them by their relevance. There is an option to return the top five entities according to their frequency in the document.
-
Ranker Class – Rates the relevance of each document to a given query. The score is computed using several different metrics:
-
BM25 rank between the given query and the given document.
-
Jaccard Similarity between the query and document header.
-
DSC (Dice) between the query and the document entities.
-
-
Semantic Analyzer Class – Receives the query and adds semantically similar terms to it, each one being the most similar term to each of the terms in the query. This is done to retrieve relevant documents that don’t contain the terms in the query but contain terms with similar meanings. This is implemented using an open source word embedding model (Medallia Word2vec algorithm).